Constrained Style Learning from Imperfect Demonstrations under Task Optimality
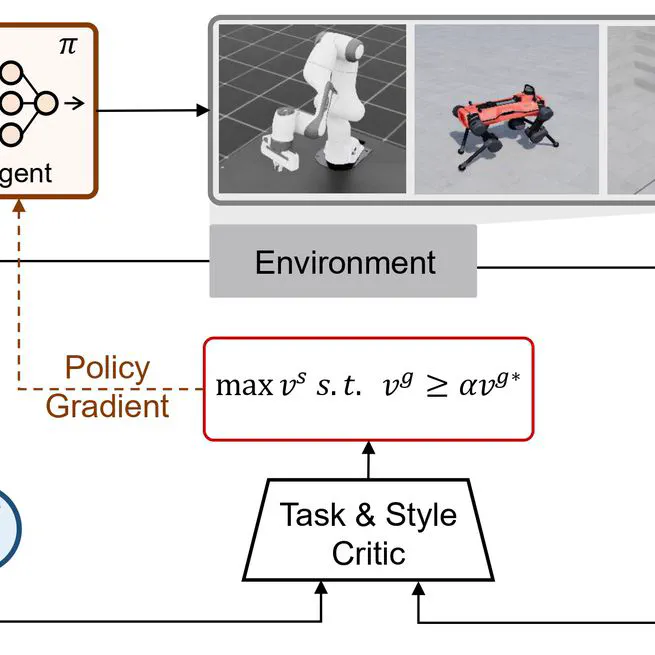
CoRL 2025. We introduce an adaptively adjustable Lagrangian multiplier to guide the agent to imitate demonstrations selectively, capturing stylistic nuances without compromising task performance. We validate our approach across multiple robotic platforms and tasks
Jul 10, 2025